
Proxmox 물음표 표시, D-State 프로세스 강제 재부팅으로 해결하기
Proxmox에 물음표가 생겨서 확인했더니 NFS 오류로 D-state인 프로세스가 생겼어요. 일반적인 재부팅이 불가능해서 특수한 방법으로 해결했습니다.

task iou-wrk blocked for more than 122 seconds.
Proxmox 위에 Immich라는 사진 백업 서비스를 구동시켜놓았습니다. 한달간 문제 없이 사용하다 사진 백업을 하던 도중 백업이 멈추어서 확인을 해보려 하니 다른 서비스들 전부 먹통이 되어 있어 웹 UI로 들어가보니 물음표가 뜨며 가상머신을 불러오지 못하는 문제가 생겼습니다.
글이 너무 어렵고 길어서 빠르게 요약했슴다.
먼저 요약해드리자면, 먼저 NFS 서버가 어떤 이유로 인해서 정지되었습니다. Proxmox는 NFS로의 연결이 필요하기 때문에 지속적인 연결 시도를 했지만, 결국 연결되지 못했고 참조할 수 없는 NFS 경로로 접근을 해야하는 프로세스의 D-State가 길어지며 커널단에서 프로세스가 응답없는 상태(Hang-up) 되었음을 표출했습니다. 문제는 응답이 없는 프로세스가 PID 1번인 systemd 였고, D-State인 프로세스는 종료가 불가능 했기에 다른 방법을 통해 강제로 재부팅 시켜 문제를 해결했습니다.
아 뭔가 쉽게 적어보고 싶은데 어렵네요.. ㅎㅎ..
혹시나 Proxmox에 물음표가 발생하고 먹통이 되었는데, 일반적인 방법으로 재부팅이 되지 않는다면 끝까지 읽어봐주세요. 그럼 이제 문제 파악 과정부터 추론, 해결 방법까지 하나씩 알아보겠습니다.
서버 오류 원인 파악하기
Proxmox 어드민 페이지로 먼저 서버 상태를 봤어요

우선 사진백업이 끊겼을 당시 Proxmox 어드민 페이지로 접속이 가능하길래 들어가보니 모든 가상머신들이 회색 물음표가 뜬 채로 아무것도 할 수 없는 상태였습니다.
노드의 가상머신이나 LVM 영역에 관한 접근을 하려고 하면 무한 로딩에 걸리며 로딩이 되지 않았습니다. 한가지 특이한 점은 데이터센터의 요약 탭에서는 아무런 값이 뜨지 않았지만 메인 노드에 접속해서 확인을 해보면, CPU, 메모리 사용량은 불러와졌습니다.
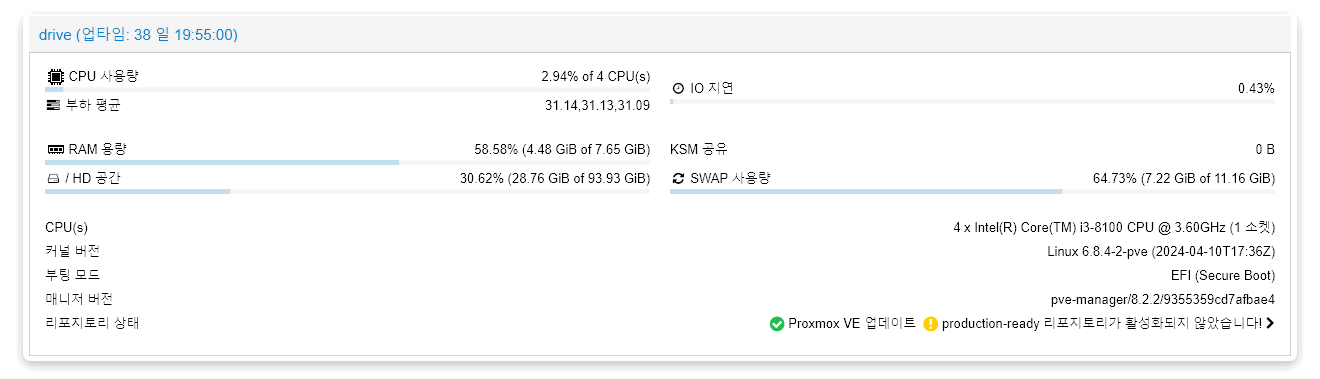
처음에는 OOM이 발생하여 문제가 생긴줄 알았으나, 저번 포스트에서 스왑공간을 늘려놨던 덕분에 메모리는 여유로운 상태였습니다. CPU 부하도 높지는 않은 상태였구요.
Proxmox에서 제공하는 웹쉘도 불러와져서 우선 일단 시스템 상의 문제가 있나 확인해보기 위해 노드에 접속해 dmesg를 요청해봤습니다.
dmesg는 "driver message"의 약자로 리눅스의 커널 로그를 표시해주는 명령어에요.커널 로그에는 부팅 과정부터 시스템이 시작되고 나서 발생하는 다양한 이벤트를 기록하고 있기 때문에 시스템의 상태를 진단하는데 도움이 되는 경우가 많아요.
하지만 dmesg에서 권한이 없다며 오류를 반환하며 웹쉘이 멈추었습니다.
dmesg: read kernel buffer failed: Operation not permitted
결국 웹 페이지를 새로고침하자 웹쉘이 다시 반겨주었는데요. 문제는 아까까지 접속했던 계정으로 다시 로그인 하려고 하자 로그인이 되지 않았습니다.
Proxmox login: root
Password: ****
Login incorrect
순간 해킹을 당한건가 싶어서 아직 웹 페이지에는 로그인이 되어 있으니 비밀번호를 변경해보려고 했습니다. 웹 페이지의 비밀번호 변경을 누르자 로딩이 길어지더니 Timeout이 발생하며 비밀번호 변경에 오류가 발생했다고 떴습니다.
이후 이미 접속된 어드민 페이지도 멈추어 새로고침하자, 여기서도 "로그인에 실패했습니다. 다시 시도해 주십시오" 라고 뜨며 접속이 되지 않았습니다.
SSH로 서버에 직접 접속해보자
더 이상 웹 상에서는 취할 수 있는 조치가 없어 SSH로 직접 서버에 접속해보았는데 다행히도 연결이 되었고 로그인도 가능했습니다. 먼저 해킹의 가능성을 확인하고자 last, lastb 명령어를 통해 root 계정에 접속한 흔적을 확인했지만, 특이사항은 없어서 해킹으로 인한 문제는 아님을 확인했습니다.
last <username> 명령어는 시스템에 로그인한 기록을 보여주는 명령어에요.lastb 명령어는 마지막으로 실패한 로그인 시도가 언제인지를 알려준답니다.그렇게 서버의 문제로 파악하고 아까 실패했던 dmesg를 다시 해보니 문제없이 출력되어 로그를 확인해보았습니다. [[1]]
[[1]]:거진 한달넘게 서버가 작동했다보니 내용이 많아서 dmesg > /home/dmesg.txt로 파일 형태로 만든 다음 scp를 통해서 받으려고 했는데 파일 전송에 자꾸만 오류가 있어서 터미널 직접 굴리며 확인했습니다... 아마 NFS로 인해서 디스크 I/O 부분에 문제가 있었던 것 같습니다.
NFS 서버로 지속적인 접속 시도가 있었어요
nfs: server 192.168.0.123 not responding, timed out
nfs: server 192.168.0.123 not responding, timed out
nfs: server 192.168.0.123 not responding, timed out
nfs: server 192.168.0.123 not responding, timed out
nfs: server 192.168.0.123 not responding, timed out
nfs: server 192.168.0.123 not responding, timed out
nfs: server 192.168.0.123 not responding, timed out
...
우선 가장 눈에 띈 것은 NFS 서버에 연결이 계속 실패했는지, 지속적으로 시도중이지만 목적지 서버가 죽어서 타임아웃으로 연결하지 못한 로그가 아주 많이 찍혀 있었습니다.
Task blocked for more then 120 seconds
INFO: task iou-wrk-2537987:182381 blocked for more than 122 seconds.
Tainted: P O 6.8.4-2-pve #1
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
task:iou-wrk-2537987 state:D stack:0 pid:182381 tgid:2537923 ppid:1 flags:0x00004000
Call Trace:
__schedule+0x401/0x15e0
? psi_group_change+0x1fb/0x460
? __perf_event_task_sched_in+0x88/0x200
...
그리고 NFS 연결 실패 로그 중간에 일종의 커널 패닉?으로 보이는 로그가 확인되었습니다.
D-State(Uninterruptible Sleep) 상태에 빠졌어요
top 명령어로 실행중인 프로세스를 확인하자[[2]], 26개의 좀비 프로세스와 함께 systemd 프로세스 상태가 D 로 표시되는 것을 확인할 수 있었습니다.
[[2]]: systemctl 도 그렇고 top 명령어를 요청하고 5분 정도 가만히 지나서야 내용이 출력되었습니다. 어디선가 I/O 지연시간이 늘어나서 그런가 싶었는데, pveperf 를 확인해봐도 I/O 지연시간은 없었던 부분이라 아직도 의문입니다.
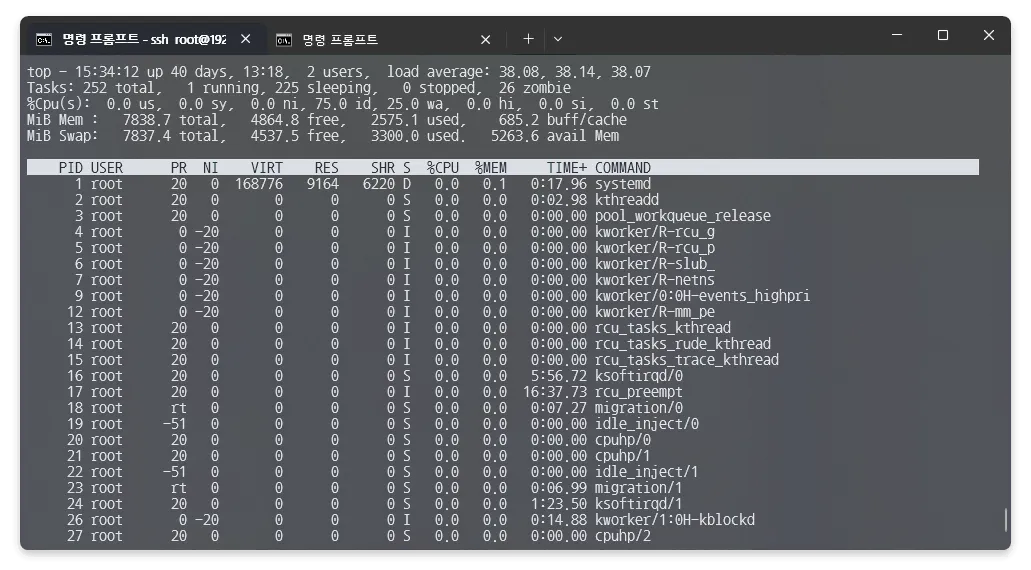
여기서 Uninterruptible Sleep 라고 불리는 D-State 란, 프로세스가 특정 이벤트나, 리소스를 기다리고 있는 상태로 작업이 끝나기 전까지는 프로세스의 종료를 포함한 어떠한 일도 불가능한 상태를 말합니다.
이번에 운영체제를 배우며 알게 된 내용을 바탕으로 조금 더 설명을 곁들이자면, 컴퓨터는 여러 프로세스가 동시에 작업을 할 수 있도록 설계되어 있지만, 일반적으로 CPU나 메모리 같은 하드웨어 리소스는 한정되어 있습니다. 그래서 여러 프로세스가 동시에 리소스를 사용하려고 할때 효율적으로 리소스를 할당해주기 위해서 스케줄링을 사용합니다.
스케줄링은 프로세스가 특정 리소스를 사용하려고 하지만 불가능한 상황일때 대기 상태로 전환시켜 리소스를 사용할 수 있는 상태가 되기 전까지 대기 상태로 두어, 리소스를 기다리는 프로세스가 사용중인 자원을 아낄 수 있어 효율적으로 리소스를 분배할 수 있는 방식입니다.
그렇기 때문에 일반적인 상황이라면 리소스를 먼저 점유중인 프로세스가 작업을 끝내고 대기중인 프로세스에게 리소스가 할당되기까지 극히 작은 시간동안만 D 상태로 전환되어 있는것이 정상이지만, 제 상황에서는 프로세스가 D 상태에서 계속 빠져나오지 못하고 갇혀 있었습니다.
아무튼, 프로세스의 종료도 불가능 하니 어떤 문제로 프로세스가 D 상태에 빠져들었는지 알아봤습니다.
ps -o pid,wchan 1
PID WCHAN
1 access_remote_vm
access_remote_vm 을 대기중인 것으로 확인했는데, 아마 VM에 연결을 계속 시도 중인 것으로 생각했습니다.
오류 원인 추정하기
받아온 파일을 NFS로 전달할 수 없어요
원인을 다시 분석해보자면, 사진을 백업하던 중 백업이 멈추자 Proxmox를 확인해본 것인데, dmesg 로그에서 NFS 서비스가 지속적으로 연결을 계속 시도했지만 NFS 서버에 연결하지는 못하는 상태였습니다.
외부에서 받아온 파일을 전달하지 못하니 중간에 있는 LXC는 파일은 받아왔지만 이걸 전달해줄 목적지가 없어 처리하지 못하는 상태가 되어 작업이 계속 지연되고 있었던 것 같습니다.
결국 Proxmox 시스템 전체가 마비되었어요
완전히 격리된 VM과 달리 LXC는 Proxmox에 종속되어 있다보니 LXC의 I/O 지연이 시스템 전체에 영향을 끼친 것 같습니다. 제가 어드민 페이지에 접속한 지점이 이 쯤 되겠네요.
Proxmox를 상태를 불러오는 프로세스인 pvestatd 도 디스크에 여유 공간이 없으니 오류가 발생해서 어드민 페이지로 접속했을때 내용을 불러오지 못해 물음표를 띄우고, LXC와 VM의 세부 내용을 불러오지 못했던 것 같습니다. 결국 파일시스템 오류가 지속되자 교착상태에 빠져 다른 Proxmox 관련 프로세스도 멈춘 것으로 보입니다.
서버 복구시키기
NFS를 다시 연결시켜주면 해결될 것 같아요
일단 추정한 대로 NFS에서 문제가 있는것이라 하면, 연결에 실패한 NFS를 다시 연결시켜주면 문제가 해결될 것 같습니다.
하지만 목적지 NFS 서버는 VM 상에서 구동되고 있었고, VM 을 다시 켜려면 Proxmox가 작동해야만 가능한 일이었기에, 지금 상황은 서로 교착 상태(Deadlock)에 빠졌다고 볼 수 있을 것 같습니다.
Proxmox가 작동되기 위해서는 Proxmox 아래의 가상머신이 필요하고, 가상머신이 작동되기 위해서는 Proxmox가 제대로 작동해야 되는 일이기 때문이죠.
그래서 NFS를 다시 연결시켜줄 수는 없는 상태인 것을 확인했습니다. 혹시나 나중에 서비스를 구축하거나 한다면 파일시스템을 제공하는 서버는 절대 가상머신 내에서 서로 참조하지 않도록 만들어야 될 것 같네요.
그러면 서버를 껐다가 켜보는게 제일 좋지 않을까요?
아무튼 NFS를 연결시켜줄 방법은 없으니 모든걸 내려놓고 systemctl reboot 명령어로 서버를 재부팅하려고 했습니다.
systemctl reboot
Failed to set wall message, ignoring: Transport endpoint is not connected
Call to Reboot failed: Transport endpoint is not connected
하지만 systemctl 명령어에서 Transport endpoint is not connected 오류를 반환하며 재부팅을 할 수 없는 상태가 되었고, halt, init 0 등의 종료 명령어도 동일한 오류를 반환했습니다.
아마도 파일시스템의 문제인지, systemd 프로세스가 D-state 여서 그런건지 systemctl 이 정상적으로 작동하기 위해서 필요한 파일에 접근하지 못하는 것 같았습니다.
결국 물리적으로 전원버튼을 눌러 껐다 켜지 않는 이상 서버를 재부팅하거나 종료할 수 없는 상태가 되었습니다.
여기서 문제는 아직 군 복무중이라... 직접 서버를 조작할 수 있는 방법이 SSH로 연결된 터미널 말고는 당장 아무것도 없기에 다른 방법을 찾아보기로 했습니다.
systemctl 없이 강제로 서버 재부팅 시키기
systemctl 이 먹통이라, systemctl 을 거치지 않고 리눅스를 강제로 재부팅하기 위해 의도적으로 패닉을 일으켜 시스템을 재부팅 시키는 방법을 사용했습니다.
/proc/sys/kernel/panic 을 1로 설정해서 커널 패닉이 발생한 후 1초 뒤에 바로 재부팅을 하도록 설정하고, /proc/sysrq-trigger 에 c 를 전달해 리눅스를 즉시 재부팅하도록 만들어줍니다.
echo 1 >/proc/sys/kernel/panic
echo c >/proc/sysrq-trigger
Session Disconneted.
echo c >/proc/sysrq-trigger 명령어는 시스템을 정리하는 과정 없이 즉시 재부팅이 되어버리기 때문에 컴퓨터의 리셋버튼을 눌러 재부팅 하는것에 준하는 위험을 가질 수 있어요. 그러니 서버에 작업중인 내용이 있다면 신중히 확인하고 명령어를 입력하는게 좋습니다.해결!
재부팅 후 SSH로 접속해보니 systemctl 도 문제 없이 작동하였고, D-State인 프로세스도 없었습니다. Proxmox 어드민 페이지에도 문제 없이 로그인이 가능했구요.
거의 이틀동안 머리 싸매고 고민했지만, 덕분에 잘못된 서버 구성으로 서비스가 어떻게 마비될 수 있는지 확인해볼 수 있는 기회였다고 생각합니다. 추후에 서버를 구성할 일이 생긴다면 안정성과 관리의 용이성을 균형있게 고려해서 첫 단추부터 잘 설계 해야할 것 같습니다.
우선 서버 구성을 당장은 변경하지 않고 추후 서버 상태를 모니터링 하면서 같은 문제가 다시 발생하는지 살펴보고 추정한 원인이 맞는지 확인해 볼 생각입니다.
레퍼런스
