포인터와 연결된 구조

포인터 (Pointer)
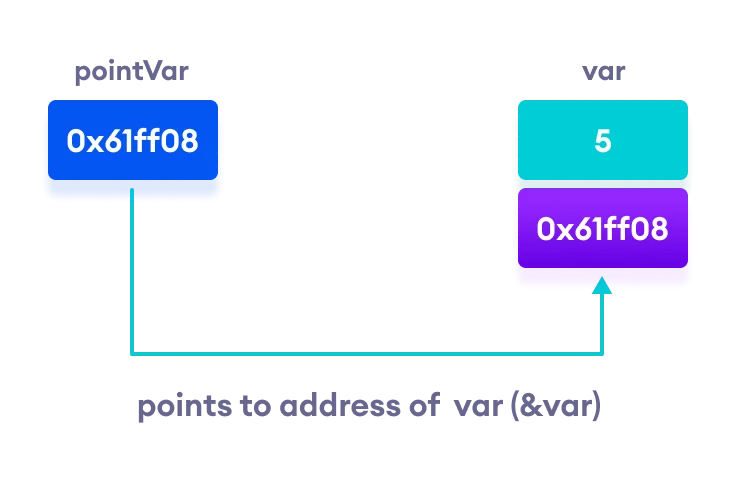
- 메모리의 주소를 저장하는 변수
- ex) 집배원이 택배를 배달할 때, 택배 송장의 '주소'를 보고 집을 찾아가는 것과 유사하다. 포인터는 데이터가 실제로 저장된 '주소'를 가지고 있으며, 이를 통해 데이터에 접근한다.
포인터를 사용하는 이유
- 기억 공간의 효율적 사용: 필요한 만큼만 동적으로 메모리를 할당하고 해제하여 메모리 낭비를 줄임
- 프로그램 성능 개선: 복잡한 자료구조(연결 리스트, 트리 등)를 구현하여 데이터 접근 및 조작 속도를 높일 수 있음. 함수 간 큰 데이터 전달 시 주소만 넘겨 오버헤드를 줄임
포인터 변수 선언
- 변수를 사용하기 전에 선언하는 것처럼 포인터도 사용하기 전에 선언해야 한다.
int score = 95; // 'score'라는 이름의 집에 95점 보관
int* score_ptr; // 'score_ptr'은 정수형 데이터의 집 주소를 저장할 수 있는 송장
score_ptr = &score; // 'score_ptr' 종이에 'score' 집의 주소를 적음
// 'score_ptr' (주소)를 통해 'score' 집 (값)에 접근
// *score_ptr은 score_ptr에 적힌 주소로 찾아가서 그 안의 내용(95)을 읽는 것과 같음
- 여러 개의 포인터 변수 선언 시 주의점
char* name1_ptr, name2, name3;: // name1_ptr은 char*형 포인터, name2와 name3은 char형 변수
char *task_ptr, *next_task_ptr, *prev_task_ptr;: // task_ptr, next_task_ptr, prev_task_ptr 모두 char*형 포인터
다양한 자료형에 대한 포인터
- 포인터는 가리키고자 하는 변수의 자료형에 맞춰 선언하며, 기본 자료형(int, float, char)뿐만 아니라 구조체, 배열 등 다양한 자료형을 가리킬 수 있다.
int* task_priority_ptr;: // int형 할 일의 우선순위 주소를 저장할 포인터
float* song_duration_ptr;: // float형 노래 재생 시간의 주소를 저장할 포인터
char* user_name_ptr;: // char형 (또는 문자열의 시작)의 주소를 저장할 포인터 (사용자 이름)
Polynomial* poly_ptr;: // Polynomial 구조체의 주소를 저장할 포인터 (수학 다항식 표현)
배열의 이름은 상수 포인터
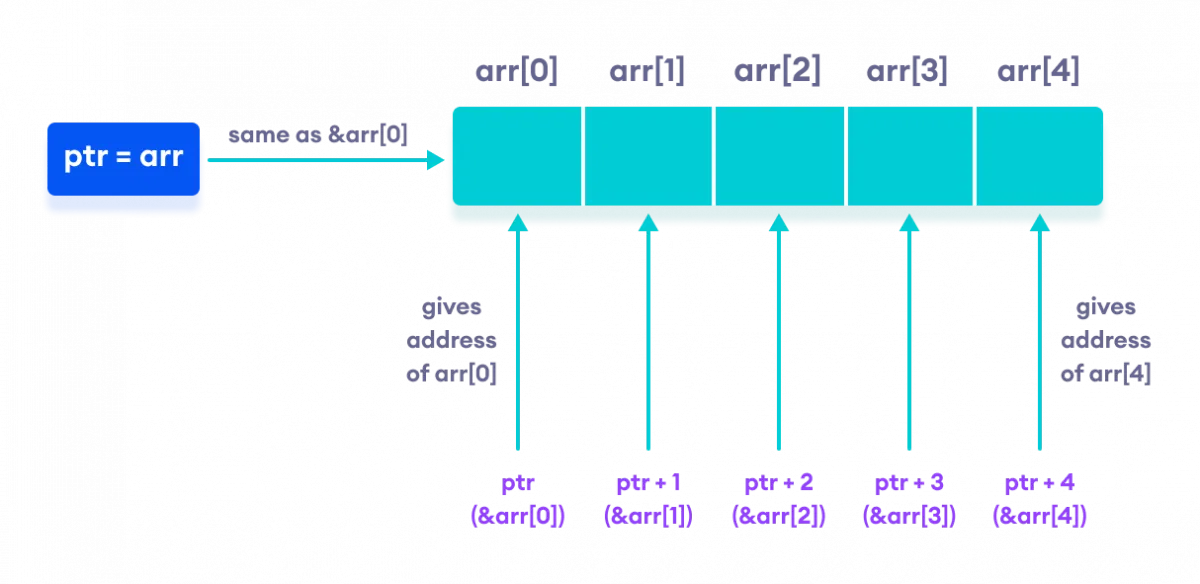
- 배열의 이름은 배열의 첫 번째 요소의 주소를 나타내는 상수 포인터로 취급된다.
- 즉,
arr과&arr[0]은 같은 주소값을 가진다. - 배열 이름은 상수이므로 주소값을 변경할 수 없다. (
arr = 다른주소;→ 오류)
int task_completion_rates[5];
int *ptr = task_completion_rates; // ptr은 task_completion_rates[0]의 주소를 가리킴
// 이는 ptr = &task_completion_rates[0]; 과 동일
ptr[3] = 80; // task_completion_rates[3] = 80; 과 동일
// A[i] == *(A+i)
// p[i] == *(p+i)
// task_completion_rates = &some_other_int_var; // 오류! 배열 이름은 주소를 바꿀 수 없음
이중 포인터
- 포인터 변수 자체도 메모리 공간을 차지하므로, 다른 포인터가 이 포인터 변수의 주소를 가리킬 수 있다. 이를 이중 포인터라 한다.
- 숨겨둔 보물(
p)의 위치를 가리키는 지도(int* p)가 있고, 그 지도가 어디에 있는지 알려주는 쪽지(int** pp)가 있는 상황이라 볼 수 있다.
char* current_task = "자료구조 공부";
char** task_list_manager = ¤t_task; // task_list_manager는 current_task 포인터의 주소를 가짐
// *task_list_manager == current_task (주소)
// **task_list_manager == *current_task (실제 문자열 "자료구조 공부")
| 표현 | 자료형 | 동일한 표현 (의미상) | 설명 |
|---|---|---|---|
10 |
int (상수) |
숫자 10 | |
i |
int |
*p, **pp |
변수 i의 값 (만약 p=&i, pp=&p 라면) |
p |
int* |
*pp, &i |
포인터 p의 값 (즉, i의 주소) |
pp |
int** |
&p |
이중 포인터 pp의 값 (즉, p의 주소) |
포인터에 대한 연산자
역참조 연산자 * 와 주소 연산자 &
&(주소 연산자): 변수 앞에 사용하여 해당 변수의 메모리 주소를 가져온다.*(역참조 연산자): 포인터 변수 앞에 사용하여 해당 포인터가 가리키는 메모리 위치의 값을 가져오거나 수정한다.
int now_track_number = 5;
int* playlist_ptr = &now_track_number; // playlist_ptr에 now_track_number의 주소를 저장
*playlist_ptr = 10; // playlist_ptr이 가리키는 곳(now_track_number)의 값을 10으로 변경
// 이는 now_track_number = 10; 과 동일한 효과
* 연산자와 & 연산자의 다양한 사용 예
*연산자result = val1 * val2;: 곱셈 연산자로 사용int *ptr;: 포인터 변수 선언에 사용*ptr = 100;: 포인터의 역참조 연산자로 사용 (ptr이 가리키는 곳의 내용)
&연산자result = byte1 & byte2;: 비트 단위 AND 연산자로 사용ptr = &variable;: 변수의 주소 추출 연산자로 사용int &ref = variable;: C++에서 참조자 선언에 사용
포인터에 대한 사칙연산
- 포인터에 정수를 더하거나 빼면, 포인터가 가리키는 자료형의 크기만큼 메모리 주소가 이동한다.
- ex)
int* ptr;일 때ptr + 1은 현재 주소에서sizeof(int)만큼 증가한 주소를 의미 - 비유: 아파트 동 호수에서 옆집으로 이동하는 것과 비슷.
101호 + 1은102호가 되는 것처럼, 포인터 연산은 다음 데이터 단위로 이동
- ex)
int playlist_ids[5] = {10, 20, 30, 40, 50}; // 노래 ID 목록
int *current_song_ptr = &playlist_ids[2]; // 현재 3번째 노래 ID (30)를 가리킴 (0-indexed)
// current_song_ptr 은 playlist_ids[2]의 주소 (예: 0x1008)
// *(current_song_ptr - 1) 은 playlist_ids[1]의 값 (20)
// *(current_song_ptr + 1) 은 playlist_ids[3]의 값 (40)
포인터와 증감 연산자
*p++:p가 가리키는 값을 가져온 후, 포인터p를 다음 메모리 주소로 증가 (자료형 크기만큼)*p--:p가 가리키는 값을 가져온 후, 포인터p를 이전 메모리 주소로 감소(*p)++:p가 가리키는 값을 가져와서, 그 값 자체를 1 증가*++p: 포인터p를 먼저 다음 주소로 증가시킨 후, 그 증가된 주소가 가리키는 값을 가져옴*--p: 포인터p를 먼저 이전 주소로 감소시킨 후, 그 감소된 주소가 가리키는 값을 가져옴
포인터의 종류
void *p;: 특정 자료형을 지정하지 않은 포인터, 어떤 형의 주소든 저장 가능하나, 역참조 시에는 반드시 형 변환 필요int *pi;:int형 변수를 가리키는 포인터float *pf;:float형 변수를 가리키는 포인터char *pc;:char형 변수 또는 문자열의 시작을 가리키는 포인터int **pp;:int*형 포인터 변수를 가리키는 이중 포인터void (*f)(int);:int형 매개변수를 받고void를 반환하는 함수를 가리키는 함수 포인터
포인터의 형 변환
- 한 종류의 포인터를 다른 종류의 포인터로 변환할 수 있다.
void* generic_item_ptr;
int specific_item_id = 123;
generic_item_ptr = &specific_item_id;
// int retrieved_id = *generic_item_ptr; // 오류! void*는 직접 역참조 불가
int retrieved_id = *( (int*)generic_item_ptr ); // int*로 형변환 후 역참조
구조체의 포인터
- 구조체 변수를 가리키는 포인터를 사용하여 구조체 멤버의 값에 접근할 수 있다.
- 멤버 접근:
(*pointer_name).member_name또는pointer_name->member_name
typedef struct {
char title[100];
int duration_seconds;
} Song;
Song current_song;
Song* song_ptr = ¤t_song;
// (*song_ptr).duration_seconds = 180;
song_ptr->duration_seconds = 180; // 현재 노래의 재생 시간을 180초로 설정
strcpy(song_ptr->title, "Yesterday"); // 현재 노래의 제목을 "Yesterday"로 설정
자체 참조 구조체
- 구조체 내부에 자기 자신과 동일한 타입의 구조체를 가리키는 포인터 멤버를 갖는 구조체
- 연결 리스트, 트리 등의 자료구조를 만드는 데 핵심적
- ex)
struct ListNode { int data; struct ListNode* next_node; };- 비유: 기차 칸이 다음 기차 칸을 연결하는 고리(포인터)를 가지고 있는 것과 같음. 각 칸(
ListNode)은 데이터(data)와 다음 칸을 가리키는 연결 고리(next_node)로 구성
- 비유: 기차 칸이 다음 기차 칸을 연결하는 고리(포인터)를 가지고 있는 것과 같음. 각 칸(
// TODO 리스트의 각 항목을 표현하는 노드
typedef struct TodoNode {
char task_description[200];
struct TodoNode* next_task; // 다음 할 일을 가리키는 포인터
} TodoNode;
// TodoNode task1, task2;
// strcpy(task1.task_description, "자료구조 복습");
// task1.next_task = &task2; // task1 다음에는 task2가 연결됨
포인터 사용 시 주의사항
- NULL 초기화: 포인터 변수는 선언 시
NULL로 초기화하는 것이 좋다. 이는 포인터가 현재 아무것도 가리키지 않음을 명시int* ptr = NULL;int* ptr = nullptr;C++ 에서는nullptr을 써도 된다.
- 초기화되지 않은 포인터 접근 금지:
NULL이거나 유효한 메모리 주소를 가리키지 않는 포인터를 역참조하면 프로그램 오류 발생char* text_ptr; *text_ptr = 'A';:text_ptr이 어디를 가리키는지 모름.- 주소가 적히지 않은 택배를 들고 배달하려는 것과 같다. 어디로 가야 할지 몰라 아무 집에다 그냥 배달할 수 있다.
- 명시적 형 변환: 다른 타입의 포인터 간 대입 시에는 명시적 형 변환을 사용해야 안전
float_ptr = (float*)int_ptr;
동적 할당
정적 메모리 할당
- 프로그램 컴파일 시 메모리 크기가 결정되고, 프로그램 실행 중에는 변경 불가
- 변수 선언 시 자동으로 메모리가 할당되고, 해당 변수의 유효 범위(scope)가 끝나면 자동으로 해제
- 장점: 개발자가 메모리 관리에 신경 쓸 필요가 적음
- 단점
- 실행 중 크기 변경 불가: 더 큰 입력 처리 못함.
- 공간 낭비 또는 부족: 너무 크거나 작게 잡으면 문제
- 식당에서 미리 정해진 수의 테이블(고정 크기)만 준비해두는 것. 손님이 적으면 빈 테이블이 낭비되고, 너무 많으면 다 수용하지 못함
// 정적 할당 예시
int user_id; // int형 변수 user_id를 정적으로 할당
int* temp_ptr; // 포인터 변수 temp_ptr 자체를 정적으로 할당 (가리키는 대상은 미정)
char user_name[50]; // 길이가 50인 char 배열을 정적으로 할당
// int size = 10;
// int dynamic_array[size]; // C 표준에서는 컴파일 오류
// 일반적으로 배열 크기는 컴파일 시 상수로 결정되어야 함
동적 메모리 할당
- 프로그램 실행 중에 필요한 만큼 메모리를 운영체제로부터 할당받아 사용하고, 사용이 끝나면 반납하는 기능
- 장점
- 유연한 크기 조절: 실행 상황에 맞춰 메모리 크기 결정
- 효율적 메모리 사용: 필요한 만큼만 할당받고 반납
- 단점: 개발자가 직접 메모리 생성과 해제를 관리해야 함.
동적 메모리 할당 및 해제 함수
malloc(size_t size):size바이트만큼의 메모리 블록을 할당하고, 그 시작 주소를void*타입으로 반환. 실패 시NULL반환void* malloc(int size);int* numbers = (int*)malloc(10 * sizeof(int));: 정수 10개 저장 공간 할당
calloc(size_t num, size_t size):num개의 요소, 각 요소가size바이트인 메모리 공간을 할당하고 0으로 초기화void* calloc(int num, int size);char* song_title = (char*)calloc(50, sizeof(char));: 50글자 노래 제목 공간 요청, 모두 0으로 초기화
// 동적 메모리 할당으로 TODO 리스트 항목 생성
char* new_task_description = (char*)malloc(100 * sizeof(char)); // 100자짜리 작업 설명을 위한 공간 할당
if (new_task_description == NULL) {
// 메모리 할당 실패 처리
} else {
strcpy(new_task_description, "동적 메모리 할당 공부하기");
// ... new_task_description 사용 ...
printf("새 할 일: %s\n", new_task_description);
free(new_task_description); // 사용 끝난 메모리 반납!
new_task_description = NULL; // 해제 후 포인터를 NULL로 설정하는게 좋다.
}
// 배열처럼 사용하기
int* playlist_ratings = (int*)malloc(sizeof(int) * 5); // 5개의 정수형 평점을 저장할 공간 할당
if (playlist_ratings != NULL) {
playlist_ratings[0] = 5; // 첫 번째 노래 평점
playlist_ratings[4] = 3; // 다섯 번째 노래 평점
// ...
free(playlist_ratings);
}
// 구조체 동적 할당
typedef struct { char title[50]; int year; } Movie;
Movie* my_favorite_movie = (Movie*)malloc(sizeof(Movie));
if (my_favorite_movie != NULL) {
strcpy(my_favorite_movie->title, "Inception");
my_favorite_movie->year = 2010;
// ...
free(my_favorite_movie);
}
realloc(void* ptr, size_t new_size): 이미 할당된 메모리 블록(ptr)의 크기를new_size로 변경
// 처음엔 5개의 작업만 저장 가능하도록 할당
char** todo_list = (char**)malloc(5 * sizeof(char*));
int task_count = 0;
int capacity = 5;
// ... 작업 추가 중 ...
if (task_count == capacity) {
// 용량 부족! 2배로 늘리기
int new_capacity = capacity * 2;
char** new_todo_list = (char**)realloc(todo_list, new_capacity * sizeof(char*));
if (new_todo_list == NULL) {
// realloc 실패 처리
} else {
todo_list = new_todo_list;
capacity = new_capacity;
printf("TODO 리스트 용량이 %d개로 확장되었습니다.\n", capacity);
}
}
free(void* ptr):malloc,calloc,realloc으로 할당받았던 메모리 블록(ptr)을 시스템에 반납free(numbers);:numbers가 가리키던 할당된 공간 반납
- 동적으로 할당된 메모리는 반드시 포인터 변수에 그 주소를 저장해야 한다. 그래야 나중에 사용하거나
free()로 해제할 수 있다.
⚠️
free() 함수에 관해서free(void* ptr) 함수는 ptr이 가리키고 있던 힙 영역의 메모리만 OS에 반환한다. 그 이후에도 ptr 변수 자체는 여전히 남아있으며, 이전에 가리키던 유효하지 않은 주소를 그대로 가지고 있다.이 상태를 댕글링 포인터라 부르며, 잘못된 주소 참조로 오류가 생길 가능성이 있으니
free() 이후에는 null로 초기화하는게 좋다.동적 할당을 이용한 배열구조의 스택
- 기존 배열 기반 스택은
MAX_SIZE가 고정되어 용량 확장이 어려웠다. - 데이터 저장 공간(배열)을 포인터로 선언하고,
init_stack시점에malloc으로 동적 할당한다. push연산 시 스택이 가득 찼다면 (is_full),realloc을 사용하여 배열 크기를 동적으로 확장할 수 있다.
스택 데이터 처리 (동적)
// Element는 스택에 저장될 데이터 타입 (미리 typedef 되어 있어야 함, ex: typedef int Element;)
// int MAX_SIZE = 10; // 이제 MAX_SIZE는 변수가 될 수 있음 (초기 용량)
Element* data; // 스택 데이터를 저장할 배열을 가리키는 포인터
int top;
int capacity; // 현재 할당된 스택의 용량
data는Element를 가리키는 포인터로,NULL로 초기화capacity는 현재 할당된 배열의 크기를 저장
스택 초기화 함수 (동적 할당)
void init_stack(int initial_capacity) {
capacity = initial_capacity;
data = (Element*)malloc(sizeof(Element) * capacity);
if (data == NULL) {
// 메모리 할당 실패 처리
fprintf(stderr, "메모리 할당 오류\n");
exit(1);
}
top = -1;
// ex) 처음으로 일정 크기의 메모리을 빌려서 TODO 리스트를 시작
}
삽입 연산 수정 (push)
void push(Element item) {
if (top >= capacity - 1) { // 스택이 가득 찼다면 (is_full)
capacity *= 2; // 용량을 두 배로 늘림
Element* new_data = (Element*)realloc(data, sizeof(Element) * capacity);
if (new_data == NULL) {
fprintf(stderr, "메모리 재할당 오류\n");
// 기존 데이터는 유지될 수 있으나, 더 이상 push는 불가할 수 있음
// 또는 프로그램 종료 등의 강력한 에러 처리
return; // 또는 exit(1);
}
data = new_data;
printf("스택 용량이 %d로 확장되었습니다.\n", capacity);
// ex) TODO 리스트 종이가 꽉 차서, 더 큰 종이로 옮겨 적고 계속 사용한다.
}
data[++top] = item;
// ex) 새로운 할 일을 리스트 맨 위에 추가한다.
}
// pop, peek, is_empty 등 나머지 연산은 기존 배열 스택과 유사하게 구현 가능
// is_full()은 top == capacity - 1 로 검사
// 스택 소멸 시 free(data) 필요
연결된 구조
순차 자료구조의 문제점
- 삽입/삭제 시 오버헤드: 배열과 같은 순차 자료구조는 중간에 데이터를 삽입하거나 삭제할 때, 연속적인 물리 주소를 유지하기 위해 뒤따르는 원소들을 이동시켜야 한다.
- ex) 줄 서 있는 사람들 중간에 새치기하거나 누가 빠지면, 뒷사람들이 전부 한 칸씩 이동해야 하는 번거로움
- 메모리 비효율성: 배열은 처음에 고정된 크기로 할당되므로, 사용량보다 크게 잡으면 메모리가 낭비되고, 작게 잡으면 부족해진다.
연결된 구조 (Linked Structure)

- 자료를 한군데 모아두는 대신, 메모리 여러 곳에 흩어져 저장된 요소들을 포인터(링크)로 연결하여 관리.
- 각 요소(노드)는 실제 데이터와 다음 요소를 가리키는 포인터를 함께 저장
연결된 구조의 용어
- 노드(node)
- 연결 자료구조에서 하나의 원소를 표현하는 단위 구조.
<원소, 주소>의 구조 - 데이터 필드 (data field): 원소의 값(실제 데이터)을 저장. 저장할 원소 형태에 따라 하나 이상의 필드로 구성 가능
- 링크 필드 (link field): 다음 노드의 주소를 저장. (이중 연결 리스트는 이전 노드 링크도 포함)
- 연결 자료구조에서 하나의 원소를 표현하는 단위 구조.
- 헤드 포인터 (head pointer)
- 리스트의 첫 번째 노드를 가리키는 포인터 변수
- 리스트 전체에 접근하는 시작점. 헤드 포인터를 잃으면 리스트 전체를 잃는 것과 같음
- 꼬리 노드 (tail node)
- 리스트의 마지막 노드. 단순 연결 리스트에서 꼬리 노드의 링크 필드는
NULL을 가짐
- 리스트의 마지막 노드. 단순 연결 리스트에서 꼬리 노드의 링크 필드는
연결된 구조의 장단점
- 장점
- 용이한 삽입/삭제: 특정 위치에 노드를 삽입/삭제 시, 주변 노드의 링크만 변경하면 되므로 빠르다. $O(1)$
- ex) 음악 재생 목록 중간에 새 노래를 끼워 넣을 때, 앞뒤 노래의 연결만 바꿔주면 됨.
- 연속된 메모리 불필요: 데이터들이 메모리 여기저기 흩어져 있어도 괜찮음
- 크기 제한 없음 (이론상): 메모리가 허용하는 한 계속 노드를 추가 가능
- 용이한 삽입/삭제: 특정 위치에 노드를 삽입/삭제 시, 주변 노드의 링크만 변경하면 되므로 빠르다. $O(1)$
- 단점
- 구현 복잡성: 포인터 사용으로 인해 배열보다 구현이 다소 어려울 수 있음.
- 오류 발생 가능성: 포인터 관련 오류(NULL 포인터 접근 등) 발생하기 쉬움
- 추가 저장 공간 필요: 각 데이터마다 링크를 위한 추가 메모리 공간(포인터 크기) 필요
- 느린 임의 접근: 특정 인덱스의 요소에 접근하려면 처음부터 링크를 따라 순차적으로 이동해야 함 ($O(n)$, 배열은 $O(1)$)
연결된 구조의 종류

- 단순 연결 (Singly Linked): 각 노드가 다음 노드만을 가리키는 단방향 링크를 가짐

- 이중 연결 (Doubly Linked): 각 노드가 다음 노드와 이전 노드를 모두 가리키는 양방향 링크를 가짐. 탐색 방향이 양쪽으로 가능
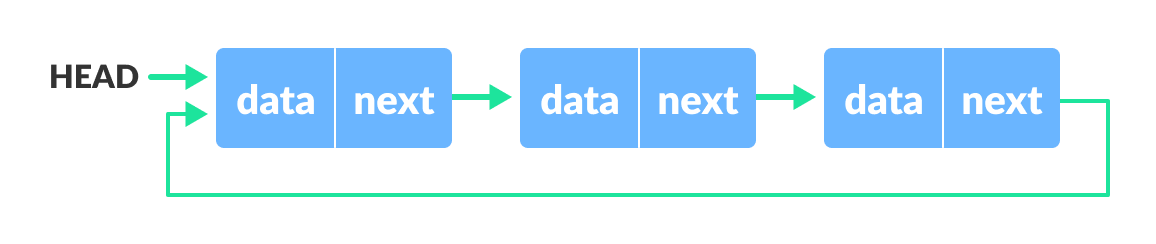
- 원형 연결 (Circular Linked): 마지막 노드의 링크가 첫 번째 노드를 가리켜 원형으로 연결됨.
NULL링크가 없음. (단순 원형, 이중 원형 가능)
배열 구조와 연결된 구조의 비교
| 특징 | 배열 구조 (순차) | 연결된 구조 |
|---|---|---|
| 요소 접근 | $O(1)$ (인덱스로 직접 접근) | $O(n)$ (처음부터 순차 탐색) |
| 용량 변경 | - 고정 크기: 낭비 또는 부족 가능성 - 동적 배열: realloc 비용 발생 |
유연함. 필요시 노드 단위로 추가/삭제. 메모리 효율적. |
| 중간 삽입/삭제 | $O(n)$ (요소 이동 필요) | $O(1)$ (링크만 변경 - 해당 위치 포인터 안다면) |
| 메모리 | 연속된 공간 필요 | 분산된 공간 사용 가능. 링크 위한 추가 공간 필요. |
| 구현 난이도 | 상대적으로 쉬움 | 포인터 사용으로 상대적 복잡. |
- 요소 접근 시간
- 배열:
A[3]접근 시,A의 시작주소 + 3 * sizeof(요소)로 바로 계산 ($O(1)$) - 연결 리스트: 4번째 요소 접근 시, 헤드부터 시작해 링크를 3번 따라가야 함 ($O(n)$)
- 배열:
- 용량 변경
- 배열: 미리 크게 잡으면 낭비, 작게 잡으면 부족.
realloc은 내부적으로 복사 과정이 있을 수 있음 - 연결 리스트: 필요할 때마다 노드를 추가하므로 공간 낭비가 적고, 메모리만 있다면 항상 삽입 가능
- 배열: 미리 크게 잡으면 낭비, 작게 잡으면 부족.
- 중간 자료 삽입/삭제
- 배열: 삽입/삭제 위치 이후 모든 자료 이동 필요. ($O(n)$)
- ex) 줄 선 사람들 사이에 누가 끼어들면 뒷사람들이 다 뒤로 물러서야 함
- 연결 리스트: 삽입/삭제할 위치의 앞 노드 링크만 변경. ($O(1)$)
- ex) 기차 사이에 새 칸을 연결할 때, 앞 칸의 뒷 연결고리와 새 칸의 앞 연결고리만 조정
- 배열: 삽입/삭제 위치 이후 모든 자료 이동 필요. ($O(n)$)
연결 리스트 (Linked List)
- 링크(포인터)를 이용해 자료들을 일렬로 나열할 수 있는 대표적인 연결 자료구조.
- 종류: 단순 연결 리스트, 원형 연결 리스트, 이중 연결 리스트, 이중 원형 연결 리스트
- 선형 리스트
week = (월, 화, 수, 목, 금, 토, 일)표현 비교- 순차 리스트 (배열) 표현
- 논리적 순서:
week[0]=월, week[1]=화, ... - 물리적 구조: 메모리에
월, 화, 수, ...데이터가 연속적으로 저장
- 논리적 순서:
- 연결 리스트 표현
- 각 요일은 하나의 노드. 각 노드는 요일 데이터와 다음 요일 노드를 가리키는 링크를 가짐
- '월' 노드는 '화' 노드를, '화' 노드는 '수' 노드를 가리킴... '일' 노드의 링크는
NULL - 메모리 상에서는 '월', '화', '수' 노드가 서로 떨어진 곳에 위치할 수 있음
- 순차 리스트 (배열) 표현
연결된 스택 (Linked Stack)
연결된 스택의 구조
- 배열 대신 연결 리스트를 사용하여 스택 구현
- 스택의
top은 연결 리스트의 헤드 포인터(첫 번째 노드) 역할을 한다. push: 리스트의 맨 앞에 새 노드 삽입pop: 리스트의 맨 앞 노드 삭제- 장점: 크기 제한이 없고, 메모리를 효율적으로 사용. 필요할 때마다 노드 생성/해제
연결된 스택의 노드 구조체
typedef struct TodoNode { // 스택의 요소(Element) 타입을 TodoNode로 가정
char task_description[100]; // 실제 데이터 (ex: 할 일 설명)
struct TodoNode* link; // 다음 노드를 가리키는 링크 (스택에서는 아래쪽 노드)
} Node; // 이제부터 Node는 이 TodoNode를 의미
Node* top = NULL; // 스택의 최상단을 가리키는 포인터, 초기에는 비어있으므로 NULL
연결 자료구조를 이용한 스택의 구현
- 스택의 원소: 단순 연결 리스트의 노드
- 스택 원소의 순서: 노드의 링크 포인터로 연결 (top이 가리키는 노드가 최상단)
push: 리스트의 맨 앞에(top에) 새 노드 삽입pop: 리스트의 맨 앞(top이 가리키는) 노드 삭제- 변수
top: 단순 연결 리스트의 헤드 포인터 역할. 스택이 비었으면NULL
스택 생성 및 연산 과정
스택에 A, B, C 순서로 push 후 pop하는 예시
- 공백 스택 생성:
top = NULL;
아직 아무것도 없는 빈 TODO 리스트 - 원소 A 삽입 (
push(A))
첫 번째 할 일 A를 적은 포스트잇을 붙임. 이게 현재 유일한 할 일- 새 노드
newNodeA생성, 데이터 A 저장 newNodeA->link = top;(현재NULL)top = newNodeA;
- 새 노드
- 원소 B 삽입 (
push(B))
두 번째 할 일 B를 적은 포스트잇을 A 위에 붙임. B가 최우선- 새 노드
newNodeB생성, 데이터 B 저장 newNodeB->link = top;(현재newNodeA를 가리킴)top = newNodeB;(이제 B가 최상단)
- 새 노드
- 원소 C 삽입 (
push(C))
세 번째 할 일 C를 적은 포스트잇을 B 위에 붙임. C가 최우선- 새 노드
newNodeC생성, 데이터 C 저장 newNodeC->link = top;(현재newNodeB를 가리킴)top = newNodeC;(이제 C가 최상단)- 스택 상태:
top -> C -> B -> A -> NULL
- 새 노드
- 원소 삭제 (
pop()) (C가 삭제됨)
가장 위에 있던 할 일 C를 완료하고 포스트잇을 떼어냄. 이제 B가 최우선removedNode = top;(C 노드를 임시 저장)top = top->link;(top = removedNode->link;즉, B를 가리키게 됨)data_C = removedNode->data;free(removedNode);(C 노드 메모리 해제)- 스택 상태:
top -> B -> A -> NULL
push 연산 (새로운 요소 e 삽입)
// Element는 스택에 저장될 데이터의 타입
void push(Element e) {
Node* new_node = (Node*)malloc(sizeof(Node));
if (new_node == NULL) {
fprintf(stderr, "메모리 할당 오류\n"); return;
}
// new_node->data = e; // Element가 구조체라면 strcpy 등 사용
// 예시: Element가 char* (문자열) TODO 항목이라고 가정
// new_node->task_description = strdup(e); // 문자열 복사 (strdup은 내부적으로 malloc)
// Element가 int라고 가정 (강의 자료와 유사하게)
new_node->data = e; // data 필드에 e 저장 (Node 구조체에 data 필드가 있다고 가정)
new_node->link = top; // 1. 새 노드의 링크가 현재 top이 가리키는 노드를 가리키도록 함
// ex) 새로 추가할 할 일(new_node) 다음에 기존의 최상단 할 일(top)을 연결
top = new_node; // 2. top 포인터가 새 노드를 가리키도록 함
// ex) 이제 새로 추가한 할 일이 리스트의 맨 앞(최상단)이 됨
}
pop 연산
Element pop() {
if (is_empty()) { // is_empty()는 top == NULL 인지 검사
fprintf(stderr, "스택 공백 에러\n");
// 실제로는 에러 코드 반환 또는 예외 처리
return ERROR_VALUE; // 적절한 에러 값 (Element 타입에 따라 다름)
}
Node* temp_node = top; // 1. 삭제할 노드(현재 top)를 임시 포인터에 저장
Element item = top->data; // 삭제할 노드의 데이터 임시 저장
top = top->link; // 2. top 포인터가 다음 노드(기존 top의 아래 노드)를 가리키도록 함
// ex) 최상단 할 일을 제거했으니, 그 다음 할 일이 새로운 최상단이 됨
free(temp_node); // 3. 삭제된 노드의 메모리 해제
// ex) 떼어낸 포스트잇(노드)은 버림
return item; // 삭제된 데이터 반환
}
peek 연산 (검색)
Element peek() {
if (is_empty()) {
fprintf(stderr, "스택 공백 에러\n");
return ERROR_VALUE;
}
return top->data; // 현재 top이 가리키는 노드의 데이터 반환 (삭제하지 않음)
// ex) 맨 위 할 일이 무엇인지 확인만 함
}
is_empty 연산
int is_empty() {
return top == NULL; // top이 NULL이면 스택은 비어있음
// ex) TODO 리스트에 아무것도 없으면 비어있는 것
}
is_full 연산
- 연결된 스택은 이론적으로 메모리가 허용하는 한 계속 노드를 추가할 수 있으므로, 배열 스택처럼 '가득 참' 상태가 명확하지 않다.
int is_full() {
return 0; // 연결 스택은 이론상 꽉 차지 않음 (malloc 실패는 다른 문제)
}
스택의 모든 노드 삭제 (destroy_stack)
- 스택 사용이 끝난 후, 동적으로 할당된 모든 노드를 해제하여 메모리 누수를 방지해야 한다.
void destroy_stack() {
while (!is_empty()) {
pop(); // pop 함수 내부에서 free가 호출됨
}
// ex) TODO 리스트의 모든 항목을 하나씩 완료(pop)하여 리스트를 완전히 비움
}
연결된 스택의 요소 수 구하기 (size)
- 스택의 현재 요소 수를 계산: top부터 시작하여
NULL을 만날 때까지 링크를 따라 노드 개수를 센다.
int size() {
Node* current = top;
int count = 0;
while (current != NULL) { // 현재 노드가 NULL이 아닐 동안 반복
count++;
current = current->link; // 다음 노드로 이동
}
// ex) TODO 리스트의 포스트잇을 맨 위부터 한 장씩 세어보는 과정
return count;
// 시간 복잡도: O(n) (스택의 모든 요소를 방문해야 함)
}
연결된 스택 요소 출력
- 입력의 역순으로 출력 (최근 입력 자료 먼저):
top부터 시작하여 링크를 따라가며 각 노드의 데이터를 출력.
void print_stack_lifo() { // LIFO: Last In, First Out
Node* current = top;
printf("스택 내용 (최상단부터): ");
while (current != NULL) {
// printf("%3d ", current->data); // Element가 int일 경우
printf("%s -> ", current->task_description); // Element가 TodoNode일 경우
current = current->link;
}
printf("NULL\n");
// ex) TODO 리스트를 맨 위 항목부터 아래로 쭉 훑어보는 것.
}
- 입력 순서대로 출력 (먼저 들어온 입력 먼저): 재귀(recursion)를 사용하거나, 다른 자료구조(예: 임시 스택 또는 큐)를 활용하여 구현 가능. 재귀를 사용한 예:
void print_stack_fifo_recursive(Node* p) { // FIFO: First In, First Out (재귀 활용)
if (p == NULL) {
return;
}
print_stack_fifo_recursive(p->link); // 가장 안쪽(바닥) 노드까지 재귀 호출
// printf("%3d ", p->data); // Element가 int일 경우, 재귀에서 돌아오면서 출력
printf("%s -> ", p->task_description); // Element가 TodoNode일 경우
}
void print_stack_fifo() {
printf("스택 내용 (입력 순서대로): ");
print_stack_fifo_recursive(top);
printf("NULL (스택의 바닥)\n");
}
연결된 큐 (Linked Queue)
단순 연결된 큐의 구조
- 큐는 FIFO(First-In, First-Out) 구조
- 단순 연결 리스트로 구현
front: 리스트의 첫 번째 노드를 가리킴 (삭제 위치)rear: 리스트의 마지막 노드를 가리킴 (삽입 위치)enqueue: 리스트의 맨 뒤(rear가 가리키는 노드의 다음)에 새 노드 삽입,rear갱신dequeue: 리스트의 맨 앞(front가 가리키는 노드) 노드 삭제,front갱신
// 큐의 노드 구조체 (스택과 동일한 Node 구조체 사용 가능)
// typedef struct Node { Element data; struct Node* link; } Node;
Node* front = NULL; // 큐의 시작(삭제 위치)을 가리킴
Node* rear = NULL; // 큐의 끝(삽입 위치)을 가리킴
원형 연결된 큐의 구조
- 단순 연결 리스트에서
rear노드의 링크가front노드를 가리키도록 하여 원형으로 만듦 - 장점:
rear포인터 하나만으로 큐를 관리할 수 있는 변형이 가능rear가 마지막 노드를 가리키고,rear->link가 첫 번째 노드(front역할)를 가리키게 함- 공백 상태와 포화 상태 구분 주의 필요
rear 포인터만 사용하는 원형 연결 큐
rear: 큐의 마지막 노드를 가리킴rear->link: 큐의 첫 번째 노드 (실제front위치)를 가리킴- 공백 상태:
rear == NULL - 노드가 하나인 상태:
rear != NULL이고rear->link == rear
enqueue(e) 연산 (원형, rear 사용)
- 큐가 비어있을 때 (
rear == NULL)
음악 재생 목록이 비어있을 때, 첫 곡을 추가하면 그 곡이 유일한 곡이자 마지막 곡- 새 노드
p생성, 데이터e저장 p->link = p;(자기 자신을 가리킴, 노드가 하나인 원형 리스트)rear = p;
- 새 노드
- 큐가 비어있지 않을 때
재생 목록의 맨 끝에 새 노래를 추가. 기존 마지막 노래는 이제 이 새 노래를 가리키고, 새 노래는 목록의 첫 노래를 가리켜 원형을 유지- 새 노드
p생성, 데이터e저장 p->link = rear->link;(새 노드가 현재 첫 번째 노드를 가리키도록 함)rear->link = p;(기존 마지막 노드가 새 노드를 가리키도록 함)rear = p;(새 노드가 새로운 마지막 노드가 됨)
- 새 노드
dequeue() 연산 (원형, rear 사용)
- 큐가 비어있을 때 (
rear == NULL): 오류 처리 - 노드가 하나만 있을 때 (
rear->link == rear)
재생 목록에 한 곡만 있을 때, 그 곡을 재생(삭제)하면 목록이 비게 됨- 삭제할 노드
p = rear;(또는p = rear->link;) item = p->data;rear = NULL;(큐가 비게 됨)free(p);
- 삭제할 노드
- 노드가 두 개 이상 있을 때
재생 목록의 첫 곡을 재생(삭제). 기존 마지막 곡은 이제 삭제된 곡 다음 곡(새로운 첫 곡)을 가리킴- 삭제할 노드
p = rear->link;(첫 번째 노드) item = p->data;rear->link = p->link;(마지막 노드가 삭제된 노드의 다음 노드(새로운 첫 번째 노드)를 가리키도록 함)free(p);
- 삭제할 노드
연결된 큐 구현 (원형, rear 사용)
// Node 구조체는 동일하게 사용
// Node* rear = NULL; // 전역 또는 큐 구조체 멤버로 선언
void enqueue_circular(Element e) {
Node* new_node = (Node*)malloc(sizeof(Node));
if(!new_node) { /* 오류 처리 */ return; }
new_node->data = e; // 또는 strcpy 등 사용
if (is_empty_circular()) { // rear == NULL
rear = new_node;
new_node->link = rear; // 자기 자신을 가리킴
} else {
new_node->link = rear->link; // 새 노드가 현재 front를 가리킴
rear->link = new_node; // 기존 rear가 새 노드를 가리킴
rear = new_node; // 새 노드가 새로운 rear가 됨
}
}
Element dequeue_circular() {
if (is_empty_circular()) { /* 오류 처리 */ return ERROR_VALUE; }
Node* temp_node = rear->link; // 삭제할 노드 (front)
Element item = temp_node->data;
if (rear == rear->link) { // 노드가 하나뿐인 경우
rear = NULL;
} else {
rear->link = temp_node->link; // rear가 삭제될 노드의 다음 노드를 가리킴
}
free(temp_node);
return item;
}
int is_empty_circular() {
return rear == NULL;
}
원형 연결 큐에서 요소의 수 구하기
rear가NULL이면 0 반환.- 아니면,
rear->link(첫 번째 노드)부터 시작하여 다시rear->link로 돌아올 때까지 (또는rear를 만날 때까지) 노드 수를 센다.
int size_circular_queue() {
if (is_empty_circular()) {
return 0;
}
int count = 0;
Node* current = rear->link; // 첫 번째 노드부터 시작
do {
count++;
current = current->link;
} while (current != rear->link); // 다시 첫 번째 노드로 돌아올 때까지
// (current가 rear->link를 한 바퀴 돌아서 다시 rear->link가 될 때까지)
return count;
}
연결된 덱 (Linked Deque)
단순 연결된 덱의 구조
- 덱(Deque)은 양쪽 끝에서 삽입과 삭제가 모두 가능한 자료구조
- 단순 연결 리스트로 덱 구현
front에서 삽입/삭제 ($O(1)$)rear에서 삽입 ($O(1)$)rear에서 삭제 ($O(n)$):rear의 이전 노드를 찾아야 하는데, 단순 연결 리스트는 단방향이므로front부터 순회해야 함.
delete_rear()연산의 한계- 단순 연결 리스트에서
delete_rear()(후단 삭제)를 $O(1)$으로 구현하기 어렵다. rear포인터만으로는rear의 이전 노드를 알 수 없기 때문- 이를 해결하려면 이중 연결 리스트를 사용해야 한다. 이중 연결 리스트는 각 노드가 이전 노드도 가리키므로
rear->prev로 $O(1)$에 접근 가능
- 단순 연결 리스트에서
레퍼런스
“이 글은 『쉽게 배우는 C 자료구조』(최영규 및 천인국, 2024)의 내용을 토대로 재구성된 자료입니다.”
Programiz: Learn to Code for Free
Learn to code in Python, C/C++, Java, and other popular programming languages with our easy to follow tutorials, examples, online compiler and references.